


汉王PDF OCR
- 版本:v8.1.4.16
- 大小:23.72MB
- 更新:2025-09-05
- 下载:39384次
- 语言:简体中文
- 授权:免费
-
评分:

- 系统:winall/win7/win10/win11
杀毒检测:无插件360通过金山通过
软件简介
 汉王 PDF OCR官方版是汉王OCR 6.0 和尚书七号的升级版,新增PDF文件的处理功能,可以把PDF文件(包括文本型和图片型)转化为可编辑的各种文档,如(PDFTOWORD)或(PDFTOTXT)。汉王 PDF OCR官方版现已全面升级,并且对个人用户免费,无功能限制。
汉王 PDF OCR官方版是汉王OCR 6.0 和尚书七号的升级版,新增PDF文件的处理功能,可以把PDF文件(包括文本型和图片型)转化为可编辑的各种文档,如(PDFTOWORD)或(PDFTOTXT)。汉王 PDF OCR官方版现已全面升级,并且对个人用户免费,无功能限制。
快捷键速记
扫描文件: 按下“Ctrl+N”调出扫描程序,扫描图像文件。
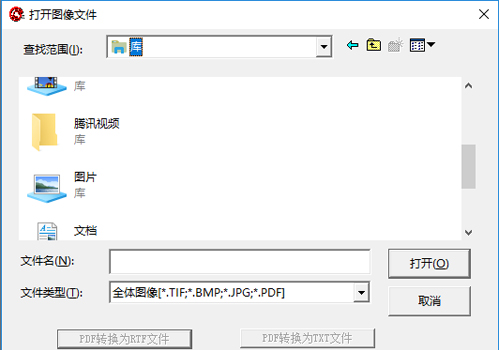
打开文件: 按下“Ctrl+O”打开图像文件,追加图像文件。
保存图像: 按下“Ctrl+S”键保存图像。
图像反白: 按下“Ctrl+I”将图像反白。
自动倾斜校正: 按下“Ctrl+D”进行自动倾斜校正。
手动倾斜校正: 按下“Ctrl+M”进行手动倾斜校正。
版面分析: 按下“F5”键,对选中的文件进行版面分析。
取消版面分析: 按下“Ctrl+Del”键,取消当前页的版面分析。
汉王PDF OCR软件特色
汉王PDF OCR官方电脑端使用方法
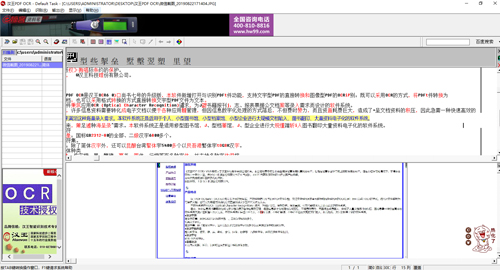
汉王PDF OCR官方电脑端常见问题

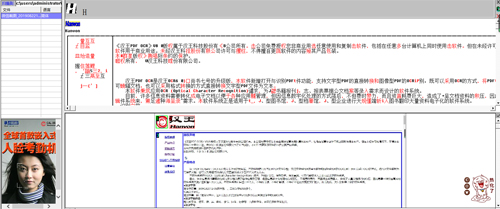
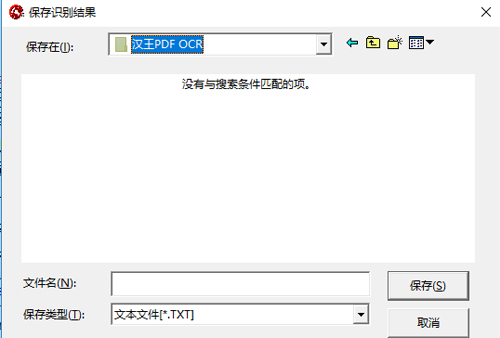
小编寄语
小知识:汉王 PDF OCR文字识别技术
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
OCR的概念是在1929年由德国科学家Tausheck最先提出来,并申请了专利。后来美国科学家Handel也提出了利用技术对文字进行识别的想法。国内最早的OCR商业应用是由中国科学家王庆人教授在南开大学开发出来的,并在美国市场投入商业使用。





相关专题



























最新软件
-
查看下载
 迅雷影音 视频播放 | 2026-07-16 天极下载站提供迅雷影音官方最新版免费下载。迅雷影音播放器官方版是迅雷官方出品的影音播放工具,原身迅雷看看播放器,拥有海量的视频资源,画质高清流畅,一直以来都深受广大朋友们的喜爱,迅雷影音播放器在迅雷看看的基础上又介入了许多新的功能,主要是体现在界面的优化,与交互设计的人性化上。视觉性能双重提升,百种格式,超清流畅播放,打造您的专属影音宝库!喜欢迅雷影音的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑!
迅雷影音 视频播放 | 2026-07-16 天极下载站提供迅雷影音官方最新版免费下载。迅雷影音播放器官方版是迅雷官方出品的影音播放工具,原身迅雷看看播放器,拥有海量的视频资源,画质高清流畅,一直以来都深受广大朋友们的喜爱,迅雷影音播放器在迅雷看看的基础上又介入了许多新的功能,主要是体现在界面的优化,与交互设计的人性化上。视觉性能双重提升,百种格式,超清流畅播放,打造您的专属影音宝库!喜欢迅雷影音的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑! -
查看下载
 全能翻译官 翻译软件 | 2026-07-16 全能翻译官是一款即时在线自动翻译器,支持在线翻译英语、日语、韩语、粤语、文言文等多种语言,并提供文档翻译、PDF翻译、图片翻译等翻译工具。全能翻译官,支持100+外语、民族语言互译,AI智能引擎翻译更准确,支持文字、文档、图片、视频、音频等多形式在线翻译,配有更多PDF、Word等文档处理工具。
全能翻译官 翻译软件 | 2026-07-16 全能翻译官是一款即时在线自动翻译器,支持在线翻译英语、日语、韩语、粤语、文言文等多种语言,并提供文档翻译、PDF翻译、图片翻译等翻译工具。全能翻译官,支持100+外语、民族语言互译,AI智能引擎翻译更准确,支持文字、文档、图片、视频、音频等多形式在线翻译,配有更多PDF、Word等文档处理工具。 -
查看下载
 CAD快速画图 CAD | 2026-07-16 CAD快速画图是一款极简风格的CAD制图软件,给你与众不同的极致体验,极简极快,支持超高分辨率、超高清、超大屏,精准测量,打印转PDF,支持超高分辨率、超高清、超大屏,小巧易用、功能强大~
CAD快速画图 CAD | 2026-07-16 CAD快速画图是一款极简风格的CAD制图软件,给你与众不同的极致体验,极简极快,支持超高分辨率、超高清、超大屏,精准测量,打印转PDF,支持超高分辨率、超高清、超大屏,小巧易用、功能强大~ -
查看下载
 鲁大师 硬件工具 | 2026-07-16 天极下载站提供鲁大师官方最新版免费下载。鲁大师是一款专业而易用并且完全免费的电脑硬件检测工具,通过跑分让用户直观地了解自己的电脑配置。鲁大师能监控用户的计算机硬件状态,了解电脑健康状况,避免硬件高温过热让计算机出现故障;同时能够分辨出用户计算机系统运行产生的垃圾文件并进行清理,全方位提升电脑性能。鲁大师拥有硬件检测、硬件测试、系统优化、节能降温、驱动安装、驱动升级、电脑检测、性能测试、实时温度检测、电池保护、电脑保护、驱动升级、手机评测等功能,感兴趣的话,可直接下载!喜欢鲁大师的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑!
鲁大师 硬件工具 | 2026-07-16 天极下载站提供鲁大师官方最新版免费下载。鲁大师是一款专业而易用并且完全免费的电脑硬件检测工具,通过跑分让用户直观地了解自己的电脑配置。鲁大师能监控用户的计算机硬件状态,了解电脑健康状况,避免硬件高温过热让计算机出现故障;同时能够分辨出用户计算机系统运行产生的垃圾文件并进行清理,全方位提升电脑性能。鲁大师拥有硬件检测、硬件测试、系统优化、节能降温、驱动安装、驱动升级、电脑检测、性能测试、实时温度检测、电池保护、电脑保护、驱动升级、手机评测等功能,感兴趣的话,可直接下载!喜欢鲁大师的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑! -
查看下载
 Windows优化大师 系统优化 | 2026-07-16 天极下载站提供Windows优化大师官方最新版免费下载。Windows优化大师是一款轻量而强大的系统优化工具,30兆集成了能想到的PC优化功能。系统优化:电脑一键优化加速_电脑问题检测,C盘/全盘清理瘦身,磁盘碎片清理,浏览器缓存清理。系统保护:系统一键全面保护_流氓软件防护,卸载残留清理,流氓弹窗拦截,上网隐私痕迹清理。喜欢Windows优化大师的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑!
Windows优化大师 系统优化 | 2026-07-16 天极下载站提供Windows优化大师官方最新版免费下载。Windows优化大师是一款轻量而强大的系统优化工具,30兆集成了能想到的PC优化功能。系统优化:电脑一键优化加速_电脑问题检测,C盘/全盘清理瘦身,磁盘碎片清理,浏览器缓存清理。系统保护:系统一键全面保护_流氓软件防护,卸载残留清理,流氓弹窗拦截,上网隐私痕迹清理。喜欢Windows优化大师的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑! -
查看下载
 海鹦OfficeAI助手 办公工具 | 2026-07-16 海鹦OfficeAI助手是一款提升50%办公效率的智能助手软件,适合使用Microsoft Office 和 WPS Office 办公的用户,提供与 Office Copilot类似的功能和使用体验。无论你是在寻找如何输入“打勾(√)符号”的方法,还是想知道“怎么在插入表格前添加文字”,或者“该用哪个公式”, AI办公助手都能为你提供快速、准确的解决方案。 通过简单的指令,ExcelAI 插件可以帮你自动完成复杂的公式计算、函数选择。 WordAI 插件还具备整理周报、撰写会议纪要、总结内容、以及文案润色的强大功能。 总之,OfficeAI 助手将大大提升你的办公效率,让日常工作变得更加轻松便捷。
海鹦OfficeAI助手 办公工具 | 2026-07-16 海鹦OfficeAI助手是一款提升50%办公效率的智能助手软件,适合使用Microsoft Office 和 WPS Office 办公的用户,提供与 Office Copilot类似的功能和使用体验。无论你是在寻找如何输入“打勾(√)符号”的方法,还是想知道“怎么在插入表格前添加文字”,或者“该用哪个公式”, AI办公助手都能为你提供快速、准确的解决方案。 通过简单的指令,ExcelAI 插件可以帮你自动完成复杂的公式计算、函数选择。 WordAI 插件还具备整理周报、撰写会议纪要、总结内容、以及文案润色的强大功能。 总之,OfficeAI 助手将大大提升你的办公效率,让日常工作变得更加轻松便捷。
猜你喜欢
-

PDF Architect
13MB/2022-09-15
查看下载 -

天若OCR文字识别
135MB/2026-06-10
查看下载 -

Infix PDF Editor
165.8MB/2025-02-11
查看下载 -

PDF修改器
3.28MB/2023-01-18
查看下载 -

PowerPoint转换成PDF转换器
14MB/2024-03-22
查看下载


热门推荐
































