


尚书七号OCR
- 版本:v1.0.0.1
- 大小:40.3MB
- 更新:2024-11-25
- 下载:209690次
- 语言:简体中文
- 授权:免费
-
评分:

- 系统:winall/win7/win10/win11
杀毒检测:无插件360通过金山通过
软件简介


尚书七号OCR软件特色
尚书七号OCR安装步骤
1、在本站下载最新安装包,按提示安装

2、安装进行中,完成即可使用

尚书七号OCR官方电脑端使用方法
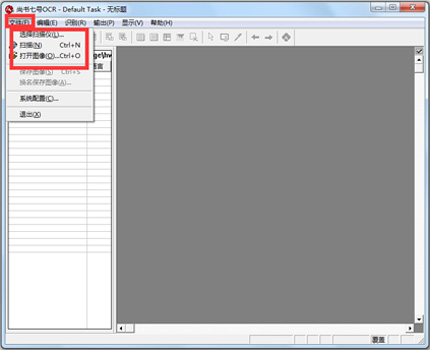
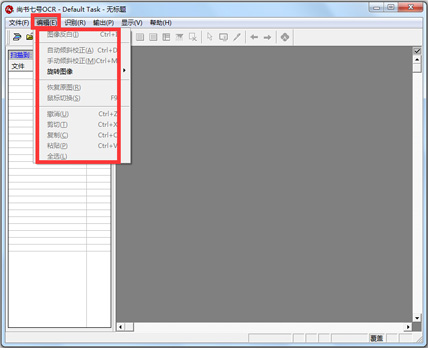
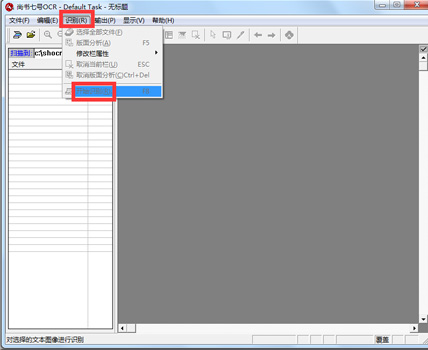
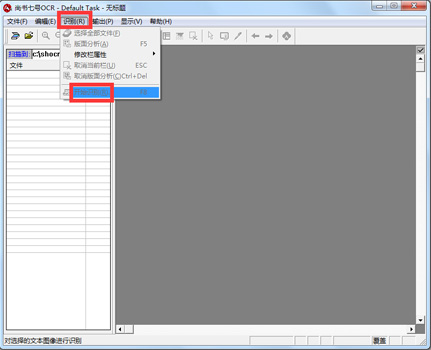
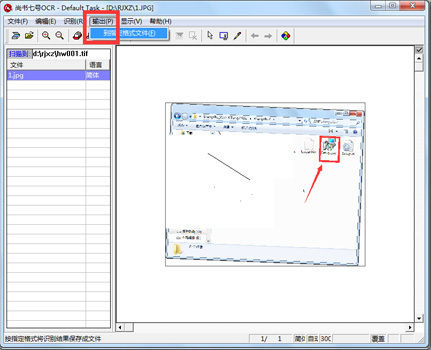
尚书七号OCR官方电脑端常见问题
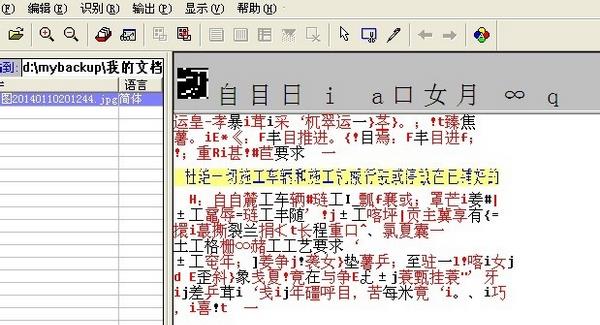


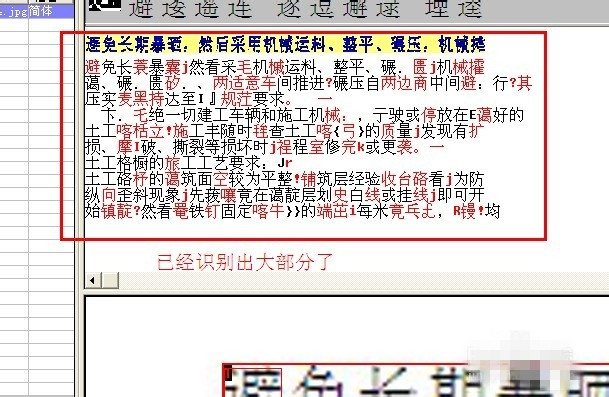
小编寄语
尚书七号应用OCR技术,为满足书籍、报刊杂志、报盘票据、公文档案等录入需求,实现系统管理方式而设计。尚书七号OCR软件适用于个人、小型图书馆、小型档案馆、小型企业进行大规模文档输入、图书翻印、大量资料电子化的软件系统。




相关专题
















最新软件
-
查看下载
 腾讯元宝官网版 AI智能对话 | 2026-07-22 腾讯元宝,是腾讯上线的基于自研大模型的C端AI助手。面向工作效率场景,腾讯元宝提供了AI搜索、AI总结、AI写作等核心能力,能够一次性解析多个微信公众号链接、网址以及PDF、word、txt等多种格式的文档,50个文件一次性解析。写报告、写方案、一键高效生成;搜咨询、搜知识、搜热点,一搜即达。更有多种绘画风格,比例参数随心替换;代码编写、数据分析等,也可轻松搞定。
腾讯元宝官网版 AI智能对话 | 2026-07-22 腾讯元宝,是腾讯上线的基于自研大模型的C端AI助手。面向工作效率场景,腾讯元宝提供了AI搜索、AI总结、AI写作等核心能力,能够一次性解析多个微信公众号链接、网址以及PDF、word、txt等多种格式的文档,50个文件一次性解析。写报告、写方案、一键高效生成;搜咨询、搜知识、搜热点,一搜即达。更有多种绘画风格,比例参数随心替换;代码编写、数据分析等,也可轻松搞定。 -
查看下载

-
查看下载
 腾讯元宝 AI智能对话 | 2026-07-22 天极下载站提供腾讯元宝PC版官方最新版免费下载。腾讯元宝,是腾讯上线的基于自研大模型的C端AI助手。面向工作效率场景,腾讯元宝提供了AI搜索、AI总结、AI写作等核心能力,能够一次性解析多个微信公众号链接、网址以及PDF、word、txt等多种格式的文档,50个文件一次性解析。写报告、写方案、一键高效生成;搜咨询、搜知识、搜热点,一搜即达。更有多种绘画风格,比例参数随心替换;代码编写、数据分析等,也可轻松搞定。喜欢腾讯元宝的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑!
腾讯元宝 AI智能对话 | 2026-07-22 天极下载站提供腾讯元宝PC版官方最新版免费下载。腾讯元宝,是腾讯上线的基于自研大模型的C端AI助手。面向工作效率场景,腾讯元宝提供了AI搜索、AI总结、AI写作等核心能力,能够一次性解析多个微信公众号链接、网址以及PDF、word、txt等多种格式的文档,50个文件一次性解析。写报告、写方案、一键高效生成;搜咨询、搜知识、搜热点,一搜即达。更有多种绘画风格,比例参数随心替换;代码编写、数据分析等,也可轻松搞定。喜欢腾讯元宝的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑! -
查看下载
 千问 AI智能对话 | 2026-07-22 天极下载站提供千问官方最新版免费下载。千问是阿里通义千问大模型打造的AI对话助手,通义千问支持问答、写作、代码、翻译、录音、PPT创作、文档处理、音视频速读。千问使用阿里最强闭源Qwen大模型,“聪明会思考”。通过极致优化的简洁界面,让你无门槛地体验到最新AI技术带来的智能升级,旨在成为你在工作、学习、生活中的最佳AI助手。喜欢千问的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑!
千问 AI智能对话 | 2026-07-22 天极下载站提供千问官方最新版免费下载。千问是阿里通义千问大模型打造的AI对话助手,通义千问支持问答、写作、代码、翻译、录音、PPT创作、文档处理、音视频速读。千问使用阿里最强闭源Qwen大模型,“聪明会思考”。通过极致优化的简洁界面,让你无门槛地体验到最新AI技术带来的智能升级,旨在成为你在工作、学习、生活中的最佳AI助手。喜欢千问的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑! -
查看下载
 精灵壁纸 屏保桌面 | 2026-07-22 天极下载站提供精灵壁纸官方最新版免费下载。精灵壁纸是一款免费壁纸软件。独家自研动态壁纸引擎,利用图像算法、粒子特效,让静态壁纸动起来,像游戏画面一样炫酷;桌面图标一键收纳,双击隐藏桌面图标 让电脑桌面整洁有序;海量超清4K视频桌面壁纸,每日更新风景护眼美女清新萌宠游戏动漫壁纸图片;深度的性能优化,自定义的高性能壁纸播放器和游戏免打扰模式,让动态壁纸的性能消耗可以忽略不计。喜欢精灵壁纸的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑!
精灵壁纸 屏保桌面 | 2026-07-22 天极下载站提供精灵壁纸官方最新版免费下载。精灵壁纸是一款免费壁纸软件。独家自研动态壁纸引擎,利用图像算法、粒子特效,让静态壁纸动起来,像游戏画面一样炫酷;桌面图标一键收纳,双击隐藏桌面图标 让电脑桌面整洁有序;海量超清4K视频桌面壁纸,每日更新风景护眼美女清新萌宠游戏动漫壁纸图片;深度的性能优化,自定义的高性能壁纸播放器和游戏免打扰模式,让动态壁纸的性能消耗可以忽略不计。喜欢精灵壁纸的家人们快来天极下载站体验,此软件已通过安全检测,无捆绑! -
查看下载
 微信输入法 拼音输入 | 2026-07-22 天极下载提供最新官方微信输入法安装包下载服务,请大家来此站下载,安全有保障。微信输入法(简洁、好用、打字快)是一款跨平台的智能输入法。支持问拼音、双拼、五笔输入;支持问AI助手、跨设备复制粘贴、同步词库和常用语。拥有智能拼写,可精准匹配候选词。你还可以设置快捷发送、剪贴板、外观、快捷键、单机模式等功能,让你的输入更快、更准。
微信输入法 拼音输入 | 2026-07-22 天极下载提供最新官方微信输入法安装包下载服务,请大家来此站下载,安全有保障。微信输入法(简洁、好用、打字快)是一款跨平台的智能输入法。支持问拼音、双拼、五笔输入;支持问AI助手、跨设备复制粘贴、同步词库和常用语。拥有智能拼写,可精准匹配候选词。你还可以设置快捷发送、剪贴板、外观、快捷键、单机模式等功能,让你的输入更快、更准。
猜你喜欢
-

PDF猫OCR文字识别
9.1MB/2024-01-15
查看下载 -

闪电OCR图片文字识别软件
51.05MB/2025-01-14
查看下载 -

转转大师OCR识别软件
30MB/2026-03-05
查看下载 -

风云OCR文字识别
1.67MB/2026-05-08
查看下载 -

诺一自媒体标题生成神器
66.9MB/2024-03-07
查看下载


热门推荐
































