

在工作中我们经常会处理各种各样的文档,比如将扫描后得到的PDF文档转换成电子版,这时候如果手动录入的话效率太低,直接将PDF转换成Word的话文字又无法编辑,这时候我们可以使用uPDF的文字识别功能,直接将扫描件转换成可编辑的PDF文档。
首先打开uPDF,选择上方的OCR文字识别功能。

点击添加文件,将扫描后的文档上传到软件中。
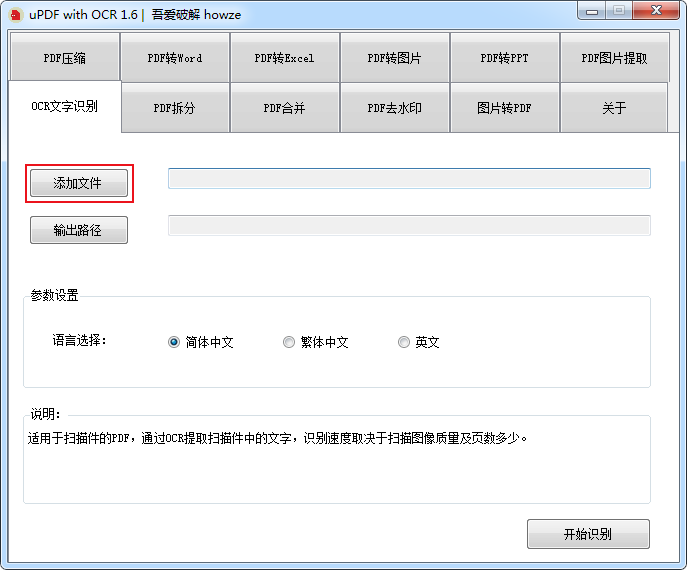
选择识别后PDF文档的存储位置和识别的语言。
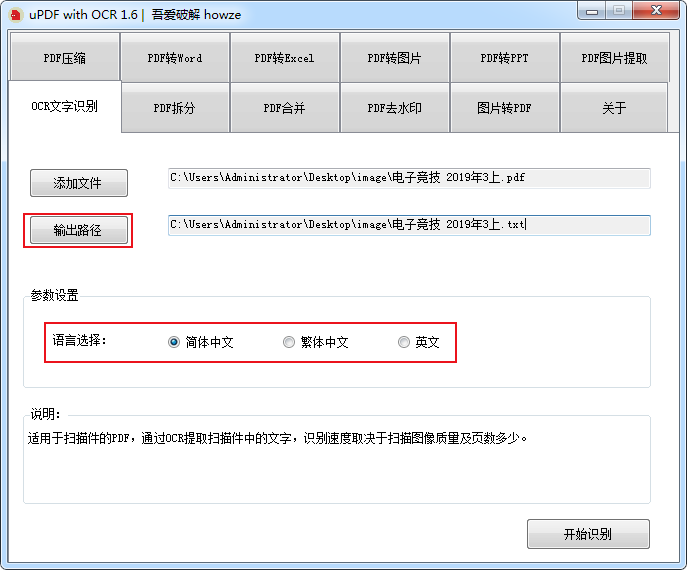
完成以上设置后,点击下方的开始识别,等待软件进行处理。
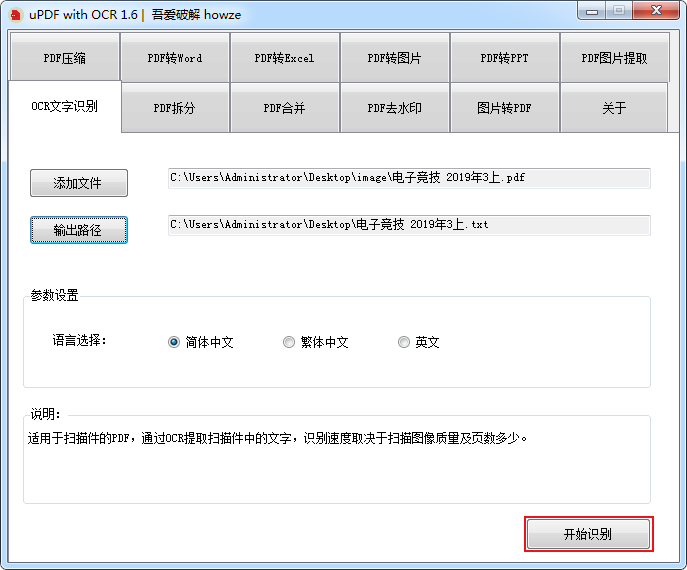
以上就是使用uPDF的OCR文字识别功能的方法,借助这个功能,我们可以快速将扫描后的文档转换成电子版文档,非常方便。







































")
")



语音转文字!新媒体翻译者都有哪些实时语音转文本工具?")





















