

今天小编给大家讲解微信小程序如何制作一个cnode?有需要或者有兴趣的朋友们可以看一看下文,相信对大家会有所帮助的。
构建准备工作
构建过程我这里直接列举一些链接的方式,因为想把主要的篇幅用来写程序的过程。
1、首先你需要注册一个微信小程序的开发平台:点这里
2、其次你需要完善你的信息,来获取AppID,如果没有AppID的话,微信小程序的有些功能是用不了的,个人的话是无法申请到的,要有企业的验证信息,不过可以看看这篇文章破解:点这里
3、需要下载一个微信开发者工具:点这里
4、前面的步骤准备好之后,开始构建我们的项目
正式开始搭建
这是我们完成之后的视图
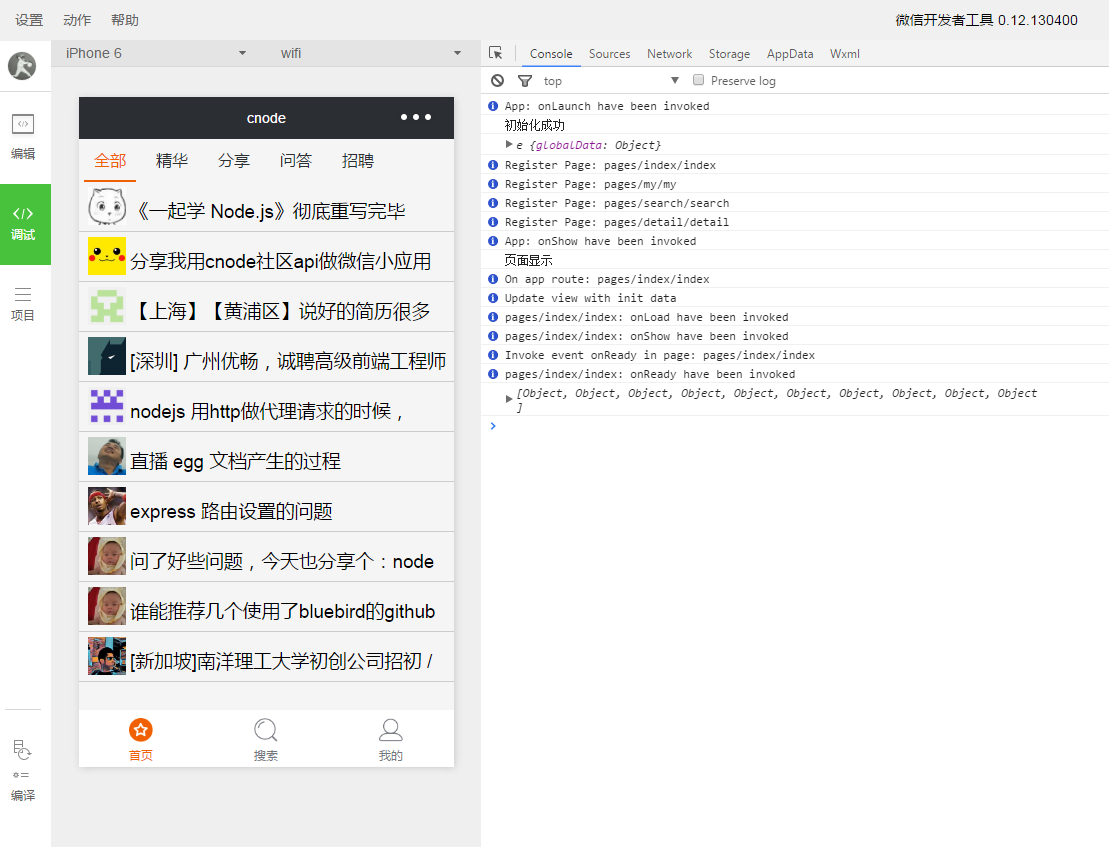
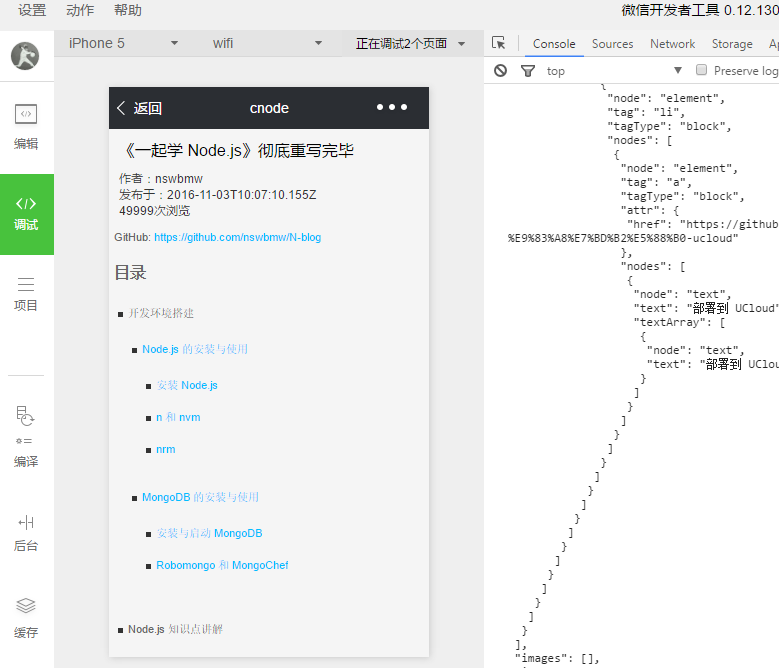
页面分析:
我们可以看到,页面的页脚有3个导航按钮,分别是首页、搜索、我的。
首页的话有5个tab切换,分别是全部、精华、分享、问答、招聘,当我们点击文章标题的时候,可以跳转到对应的详情页,按返回,可以回到上一级页面。上拉,可以加载更多。接下来我们就来完成这些功能。
小程序的开发文档在这里,可以跟着文档来看下面的代码:文档
我们的目录结构如下:
pages/
pages/index/index.wxml
pages/index/index.js
pages/index/index.wxss
pages/detail/detail.wxml
pages/detail/detail.js
pages/detail/detail.wxss
app.js
app.json
app.wxss
首先是使用app.json文件来对微信小程序进行全局配置,决定页面文件的路径、窗口表现、设置网络超时时间、设置多 tab 等。
{
"pages": [
"pages/index/index",
"pages/my/my",
"pages/search/search",
"pages/detail/detail"
],
"window": {
"navigationBarBackgroundColor":"#2b2e33","navigationBarTextStyle": "white","navigationBarTitleText": "cnode",
"backgroundColor": "#fff",
"backgroundTextStyle": "#dark"
},
"tabBar": {
"color": "#74777e",
"selectedColor": "#f06000",
"borderStyle": "white",
"backgroundColor": "#fff",
"list": [{
"pagePath": "pages/index/index",
"iconPath": "image/wp.png",
"selectedIconPath": "image/wpselect.png","text": "首页"}, {
"pagePath": "pages/search/search",
"iconPath": "image/ss.png",
"selectedIconPath": "image/ssselect.png","text": "搜索"},{
"pagePath": "pages/my/my",
"iconPath": "image/my.png",
"selectedIconPath": "image/myselect.png","text": "我的"}]
},
"networkTimeout": {
"request": 10000,
"connectSocket": 10000,
"uploadFile": 10000,
"downloadFile": 10000
},
"debug": true
}
我们在app.json中的pages来设置我们的设置页面路径,数组的第一项代表小程序的初始页面,我们的首页是初始页,所以在page中的第一个。小程序中新增/减少页面,都需要对 pages 数组进行修改。文件名不需要写文件后缀,因为框架会自动去寻找路径.json,.js,.wxml,.wxss的四个文件进行整合。
在app.json中的list中,我们从来设置tab列表,也即是页面中底部的导航栏,该list最少2个,最多5个。并且设置了对应页面路径、tab按钮的文字、icon路径,选中之后的图片路径等。
其他的配置内容可以看看文档,因为不可能全局介绍完,否则内容太多了。
注意点:
当我们跳转到详情页的时候,因为详情页是新增页面,但是底部的导航栏是没有详情这个选项的,所以我们需要在app.json中pages数组中增加详情页的路径,但是在list数组中不需要增加,否则会报错。
配置文件搞好了,接下来开始书写我们的首页
一个小程序页面由四个文件组成,分别是:js、wxml(相当于html)、wxss(相当于css)、json(页面配置),这四个文件必须具有相同的路径与文件名。
所以我们首页结构是:
pages/index/index.js
pages/index/index.wxml
pages/index/index.wxss
index.js如下:
/*
* @Author: xianyulaodi
* @Date: 2017-01-16 17:33:45
*/
//创建精选页面对象
Page({
data: {
loading: false,
loadtxt: \'正在加载\',
currentTab: \'all\',
dataList:[],
page:1,
section: [
{name : \'全部\',tab : \'all\'},
{name : \'精华\',tab : \'good\'},
{name : \'分享\',tab : \'share\'},
{name : \'问答\',tab : \'ask\'},
{name : \'招聘\',tab : \'job\'}
]
},
/*
{Number} page 页数
{String} tab 主题分类。目前有 ask share job {Number} limit 每一页的主题数量{String} mdrender 当为 false 时,不渲染。默认为 true,渲染出现的所有 markdown 格式文本。
*/
onLoad: function(){
var self=this;//这里需要注意
wx.request({
url: \'https://cnodejs.org/api/v1/topics\',data: {\'page\':self.data.page,
\'tab\':self.data.currentTab,
\'limit\':10,
\'mdrender\':true,
},
header: {
\'content-type\': \'application/json\'
},
success: function(rs) {
var dataArr=rs.data.data;
console.log(dataArr);
var dataList=self.data.dataList;
//合并数组,用于上拉加载更多,没有append方法,我这种方法不是很好,因为到后面数组会很大var renderArr=self.data.page==1 ? dataArr : dataList.concat(dataArr);self.setData({loading: true,
loadtxt: \'数据加载完成\',
dataList: renderArr
})
}
})
},
// 页面上拉触底事件的处理函数,用于上拉记载更多onReachBottom:function(e){var page=this.data.page;
// 控制一下,最多显示十页的数据
if(page<10){
this.setData({ page: page+1 });
this.onLoad();
}
return false;
},
handleTap: function(e){
//console.log(e);
let tab = e.currentTarget.id;
if(tab){
this.setData({
currentTab: tab,
page:1 //重置page为1
})
this.onLoad();
}
},
/*
使用wx.navigateTo或者直接使用它的组件navigator要注意:
在app.json里面也需要pages里面的配置里要写上跳转的路径,但是在app.json里面不需要写上这个跳转的路径。
*/
goToDetail:function(e){
var id=e.target.id;
console.log(id);
// wx.navigateTo,是保留当前页面,调到应用内某个页面,使用wx.navigateBack可以返回wx.navigateTo({url: \'../detail/detail?id=\'+id
})
}
})
代码有点长,不过没关系,我们来分析一下:
Page()函数用来注册一个页面。接受一个 object 参数,其指定页面的初始数据、生命周期函数、事件处理函数等。
Page()里面有很多的参数,不过我们只用到了其中的三个,onLoad和onReachBottom,data。
onLoad是监听页面的加载,也就是说页面一加载完成就会执行。 onReachBottom是页面上拉触底事件的处理函数,我们这里用来做上拉加载更多的操作,也就是上拉一次,请求的页码参数就加1;data是页面初始数据。
那么获取到的数据怎样传给页面呢,可以通过page()中的data参数,它是页面的初始数据。如果你想改变初始数据,比如页面请求完成了,可以通过this.setData来对初始数据进行修改。
还有对于请求参数的修改,我们不是直接传到onLoad里面,而是通过this.setData()来对初始参数就行修改,从而达到修改参数目的,比如首页上面的五个tab切换,后者是上拉加载更多的实现,都是通过这种方式来进行传值的。
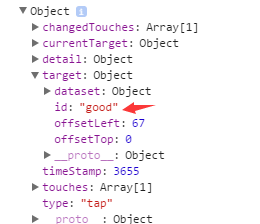
除此之外,我们还注册了两个事件,一个是handleTap,控制首页(index页)的tab切换,每次切换我们要拿到该tab对应的tab值,从而拿到该tab对应的数据。在page定义中的相应事件处理函数,参数是event。我们来看看下面的代码:
handleTap: function(event){
console.log(event);
let tab = event.currentTarget.id;
if(tab){
this.setData({
currentTab: tab,
page:1 //重置page为1
})
this.onLoad();
}
}
我们console.log(event)的内容如下:
我们注册的另一个事件是goToDetail,用来跳转到详情页,并传入一个id过去:
goToDetail:function(e){
var id=e.target.id;
// wx.navigateTo,是保留当前页面,调到应用内某个页面,使用wx.navigateBack可以返回wx.navigateTo({url: \'../detail/detail?id=\'+id
})
}
这里我们调用小程序里面提供的wx.navigateTo来跳转到详情页,它会保留当前页面,当你返回的时候可以返回上一级页面。也可以这么理解,wx.navigateTo相当于在当前页面上方加了一层遮罩,这个遮罩就是你要跳转页面,当你点击返回时,这层遮罩消失,因此你又回到了当前页。
接下来我们介绍index.wxml
代码如下:
{{item.name}}
{{item.title}}
其实跟我们的html差不错,不过它又不是html,因为在这里你不可以使用html的语法,否则会报错,而是要使用文档中规定的那些标签。可以看看文档中组件部分。
我们对里面的内容进行分析:
在WXML中,小程序提供了模板(template),可以在模板中定义代码片段,然后在不同的地方调用。
我们的index.wxml中也引入了一个loading的模板,我们来看看common/template.wxml里面的内容
{{loadtxt}}...
{{loadtxt}}...
我们定义的是一个loading的模板,这样的话在需要用到loading的地方都可以用到。不过有个前提,调用它的地方要提供和模板里面一样的数据结构。
如何使用呢,使用%20is%20属性,声明需要的使用的模板,然后将模板所需要的%20data%20传入,如:
注意点:在模本里面的文件路径是相应于引用它的页面的路径,如果图片路径被写在一个js文件A里,而B引用了这个js文件,那么图片的路径必须是相对于B的相对路径。所以,最好在公共的js文件里使用绝对路径。
继续我们的页面分析,页面的数据那里来的呢,来自于index.js的app()里面的data参数里,比如我们的data里面有section这个数组,可以用来渲染首页的tab切换,data里面有dataList这个数组,用来渲染请求返回的数据。在组件上使用wx:for控制属性绑定一个数组,即可使用数组中各项的数据重复渲染该组件。
前面我们也说了我们handleTap和goToDetail两个事件,怎样绑定在页面上呢,可以用bindTap或catchTap的方式,不过catchTap不会冒泡,使用方法是这样:
{{item.title}}
注意点:
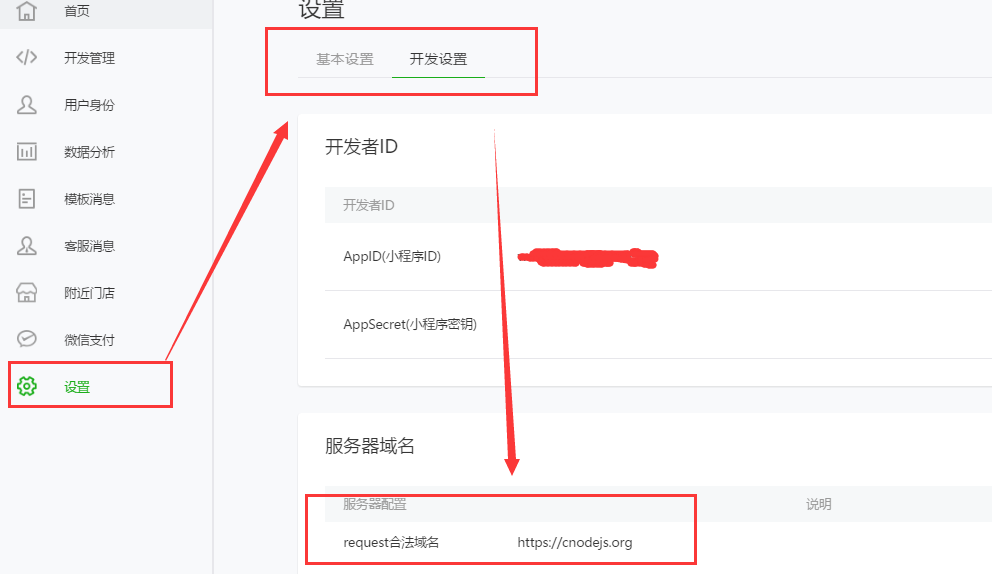
当你的小程序可以正常运行的时候,应该会有这样的一个报错;
解决方法:打开小程序微信公众平台设置小程序开发设置,配置服务器合法域名(必须是https),如下图
这样,我们的首页基本就完成了。因为css部分和正常的css一样,没啥好说的。分析一下首页的代码,发觉小程序有点借鉴react的思想,比如数据初始化还有一些page上提供的事件。如果你之前玩过react,入门起来会快很多。如果你有用腾讯的artTemplate这个js模板引擎的话,就更好理解一些。
接下来说一说详情页:
我们在首页中,通过wx.navigateTo跳转到了详情页,并传入了详情页需要的idgoToDetail:function(e){var id=e.target.id;
wx.navigateTo({
url: \'../detail/detail?id=\'+id
})
}
我们来分析一下详情页的一些内容,首先来分析它的js,也就是pages/detail/detail.js/** @Author: xianyulaodi
* @Date: 2017-01-16 17:33:45
*/
// 引入这个是为了解析详情页的html
var WxParse = require(\'../../wxParse/wxParse.js\');Page({data:{
title:\'\',
loading: false,
loadtxt: \'正在加载\',
data:{}
},
onLoad: function(params){
console.log(params); //这里是上一个跳转页面传过来的参数,可以直接获取var id=params.id;var self=this;//这里需要注意
wx.request({
url: \'https://cnodejs.org/api/v1/topic/\'+id,header: {\'content-type\': \'application/json\'
},
success: function(rs) {
console.log(rs);
var data=rs.data.data;
var content=data.content;
self.setData({
loading: true,
loadtxt: \'数据加载完成\',
data: data
});
/**
* WxParse.wxParse(bindName , type, data, target,imagePadding)* 1.bindName绑定的数据名(必填)* 2.type可以为html或者md(必填)
* 3.data为传入的具体数据(必填)
* 4.target为Page对象,一般为this(必填)
* 5.imagePadding为当图片自适应是左右的单一padding(默认为0,可选)*
*/
WxParse.wxParse(\'content\', \'html\', content, self,5);}
});
},
})
我们怎样来拿到上一个页面传过来的值呢,我们可以在onLoad时间中写一个参数,这个参数就是获取url上传过来的值,它是一个对象onLoad: function(params){console.log(params); //这里是上一个跳转页面传过来的参数,可以直接获取}
这是控制台打印的内容,这样的话,根据获取的id,我们就可以传给后台请求到对应的详情页了。
详情页和首页的原理基本差不多,不过详情页content字段返回的是html结构,微信小程序暂时还没有富文本html、md解析组件。所以如果直接渲染content的话,会直接把html标签页显示出来。
那怎么办呢,我们需要引入一个外部的从来解析html的组件wxParse,链接地址在这里:https://weappdev.com/t/wxparse-version0-2-html-markdown/326

这样的话,html的富文本就可以在页面上正常显示了。这样,我们的任务也就完成了
以上就是微信小程序如何制作一个cnode的全部内容了,大家都学会了吗?







































")
")



语音转文字!新媒体翻译者都有哪些实时语音转文本工具?")



























