


- 热门下载
- 热门分类
- 热门合集

小庄OCR图片自动识别文字
1.0官方正式版- 软件大小:0.35 MB
- 更新时间:2019-12-30
-
用户评分:

- 软件版本:1.0
- 软件语言:简体中文
- 系统类型:支持32/64位
- 软件授权:免费
- 下载次数:18次
- 杀毒检测:无插件360通过金山通过
- 运行系统:WinXP/2000/vista/Win7/Win8/Win10
本地纯净下载
纯净官方版软件简介
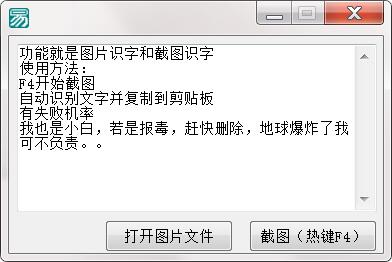
小庄OCR图片自动识别文字官方版是专业性很高而且实用性也很强的ocr识别工具,小庄OCR图片自动识别文字最新版能够帮助使用者进行图片识别和截图文字识别,可批量处理功能,避免了单页处理的麻烦。软件基于强大的识别技术,可以一键识别图片上的文字,并且可以将文字进行保存,还提供了导入图片和截图两种识别模式,并且支持使用热键进行截图识别操作。
软件构成
OCR软件只需提供与扫描仪的接口,利用扫描仪驱动软件即可。因此,OCR软件主要是由下面几个部分组成。
1、图像输入、预处理:
图像输入:对于不同的图像格式,有着不同的存储格式,不同的压缩方式。预处理:主要包括二值化,噪声去除,倾斜较正等
2、二值化:
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,我们可以简单的分为前景与背景,为了让计算机更快的,更好的识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图了。
3、噪声去除:
对于不同的文档,我们对噪声的定义可以不同,根据噪声的特征进行去噪,就叫做噪声去除
4、倾斜较正:
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
5、版面分析:
将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
6、字符切割:
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能,这就需要文字识别软件有字符切割功能。
7、字符识别:
这一研究,已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
8、版面恢复:
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变,的输出到word文档,pdf文档等,这一过程就叫做版面恢复。
9、后处理、校对:
根据特定的语言上下文的关系,对识别结果进行较正,就是后处理。
开发一个OCR文字识别软件系统,其目的很简单,只是要把影像作一个转换,使影像内的图形继续保存、有表格则表格内资料及影像内的文字,一律变成计算机文字,使能达到影像资料的储存量减少、识别出的文字可再使用及分析,当然也可节省因键盘输入的人力与时间。
| 相关软件 | 版本说明 | 下载地址 |
|---|---|---|
| 闪电OCR图片文字识别软件 | 高效精准识别提取图片中的文字 | 查看 |
| 可牛影像 | 新一代的图片处理软件 | 查看 |
| 图片工厂picosmos Tools | 多功能图像处理软件 | 查看 |
| ACDSee家庭版64位 | 海量图片一键管理,强大的批处理,AI人物模式让您的照片库更有序 | 查看 |
| QQ影像 | 图片快捷处理软件 | 查看 |
小庄OCR图片自动识别文字软件特色
小庄OCR图片自动识别文字官方电脑端使用方法
小编寄语
解压密码:mydown.yesky.com
软件图集
提示:软件图集是通过小庄OCR图片自动识别文字官网或软件客户端截图获取,主要用于分享软件价值,如有侵权请联系我们!

猜你喜欢
-

闪电OCR图片文字识别软件
51.05MB/2025-01-14
查看下载 -

可牛影像
12.49MB/2025-02-17
查看下载 -

图片工厂picosmos Tools
77.05MB/2024-10-25
查看下载 -

ACDSee家庭版64位
5.04MB/2025-03-20
查看下载 -

QQ影像
16.1MB/2024-02-06
查看下载

































